To use Large Language Models (LLMs) effectively and reliably, it’s essential to include structured generation techniques. Being able to get outputs like regular expressions, JSON, or a Pydantic data model is key for making useful software.
But what’s the real effect of using libraries like Outlines or Instructor to achieve that goal?
This post answers this question.
Goal
The main goal of this evaluation is to demonstrate the power of structured generation in the context of Function Calling, which is the ability of Large Language Models (LLMs) to call functions based on natural language instructions. We focus on the case where the LLM is given a single JSON document and is expected to make a single call.
To create this evaluation, we use the Outlines library, which transforms the problem of neural text generation into transitions between states of a finite-state machine1. Outlines allows for the creation of reliable interfaces by ensuring the structure of the generated text.
We want to explore some interesting questions: Can structured generation work better than fine-tuning for Function Calling? Can this approach allow smaller open-source models to perform as well as larger, state-of-the-art ones? The results of this evaluation will give us valuable insights into the abilities and potential of structured generation in improving the performance of LLMs across various sizes and architectures. This could potentially reshape our understanding of how to optimize for specific tasks.
Benchmark
A dataset generated from real-world data has been released2 for the construction of the Berkeley Function-Calling Leaderboard. It consists of 2,000 question-function-answer pairs across multiple languages, diverse application domains, and complex use cases3. Additionally, it includes the code to reproduce the benchmark, which serves as a sort of framework for evaluation. If you want to learn more about this outstanding initiative, we recommend reading this blog post.
Data
In the Outlines community, we decided to start with the ‘AST Simple’ category, as described by the authors:
Simple Function: The evaluation of a single function includes the simplest but most commonly seen format. The user provides a JSON function document and only one call will be invoked.
Here is an example from one of the 400 records in the Python section of this evaluation category:
question = 'Find the area of a triangle with a base of 10 units and height of 5 units.'The LLM has access to the function defined by this JSON Schema to answer the question:
{
"title": "calculate_triangle_area",
"type": "object",
"description": "Calculate the area of a triangle given its base and height.",
"properties": {
"base": {
"type": "integer",
"description": "The base of the triangle."
},
"height": {
"type": "integer",
"description": "The height of the triangle."
},
"unit": {
"type": "string",
"description": "The unit of measure (defaults to 'units' if not specified)"
}
},
"required": [
"base",
"height"
]
}The expected response:
calculate_triangle_area(base=10, height=5, unit='units')This is exactly the use case we’ve been facing in our efforts to integrate LLMs to power software.
Metric
We use the evaluation process for simple functions within the GFCL framework. This process involves comparing the output of a model directly with the expected function document and potential correct answers. Below is a flowchart that details the step-by-step evaluation process.
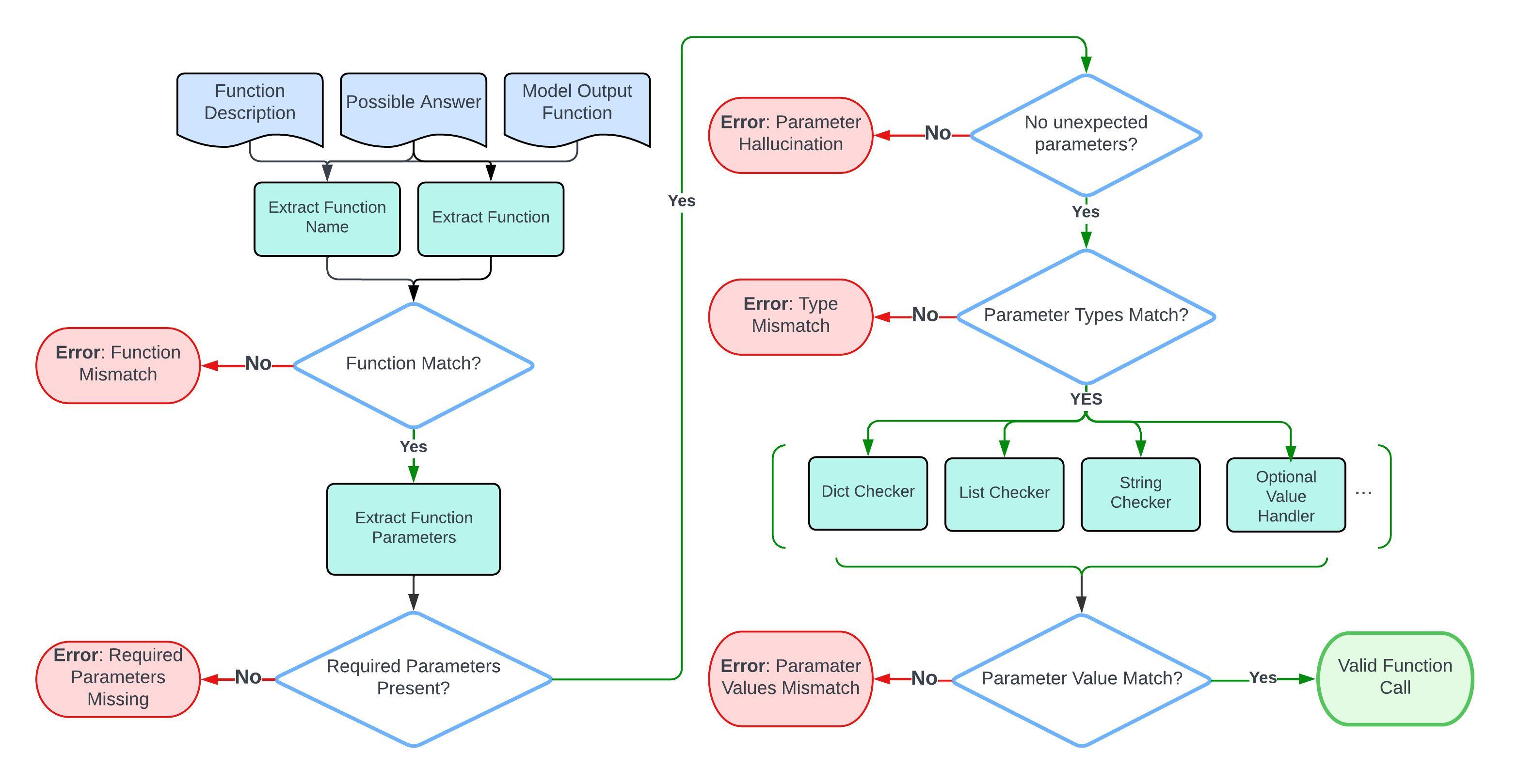
Accuracy is calculated by counting the validated function calls and comparing them with the total number of simple test category cases.
Methodology
We deployed a Modal function to run open-source models using Transformers + Outlines. Modal is an easy-to-use cloud platform to run generative AI models. Soon, we will write in more detail about our experience deploying structured generation there.
We created different model handlers to run the Gorilla BFCL evaluation framework (April 6, 2024 version) for the AST simple evaluation category.
We evaluated and reported the results comparing them with the Leaderboard Website [April 26, 2024 version].
Results
Mistral-7B-Instruct-v0.2 (5th, 85.5%)
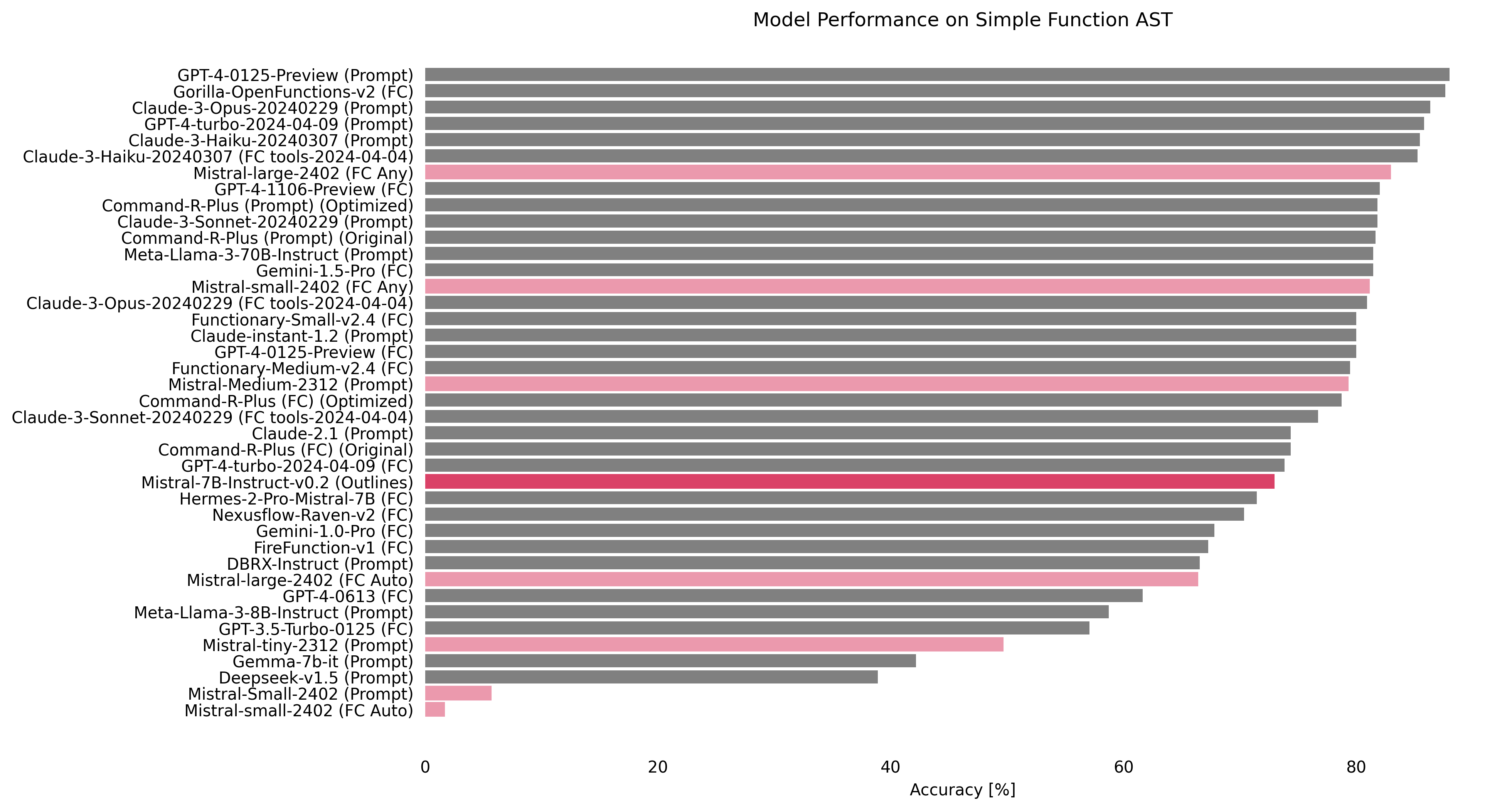
Our first intuition was to explore the potential of structured generation in enhancing the performance of a 7B model on the Function Calling task. Mistral-7B-Instruct-v0.2 achieved an impressive accuracy of 85.5%, securing the 5th position on the leaderboard. This result stands as the highest score among all Mistral models in the table, suggesting that it may play a significant role in enabling smaller models to tackle complex tasks effectively.
Gemma-7b-it (from 37th, 42.18% to 7th, 84.25%)
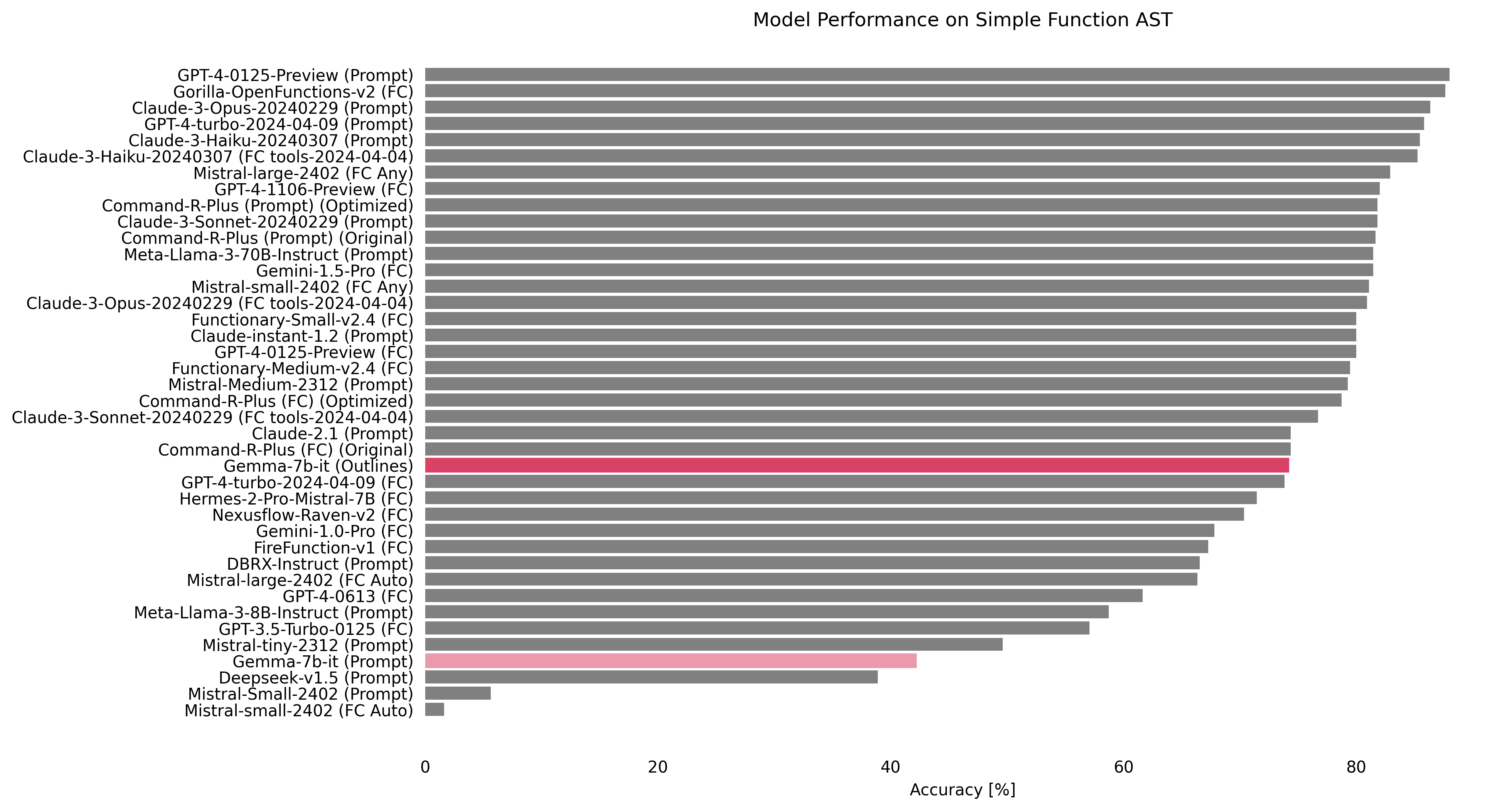
We wanted to see if a base 7B model could reach the top of the leaderboard by using the power of structured generation. google/gemma-7b-it was already the best 7B model on the leaderboard before our tests. However, when we combined it with Outlines, it showed a huge jump in performance. It went from the 37th position with an accuracy of 42.18% to 7th place, achieving an accuracy of 84.25%. This big improvement highlights the potential of structured generation to boost the performance of base models.
Deepseek-v1.5 (from 38th, 38.91% to 3rd, 87%)
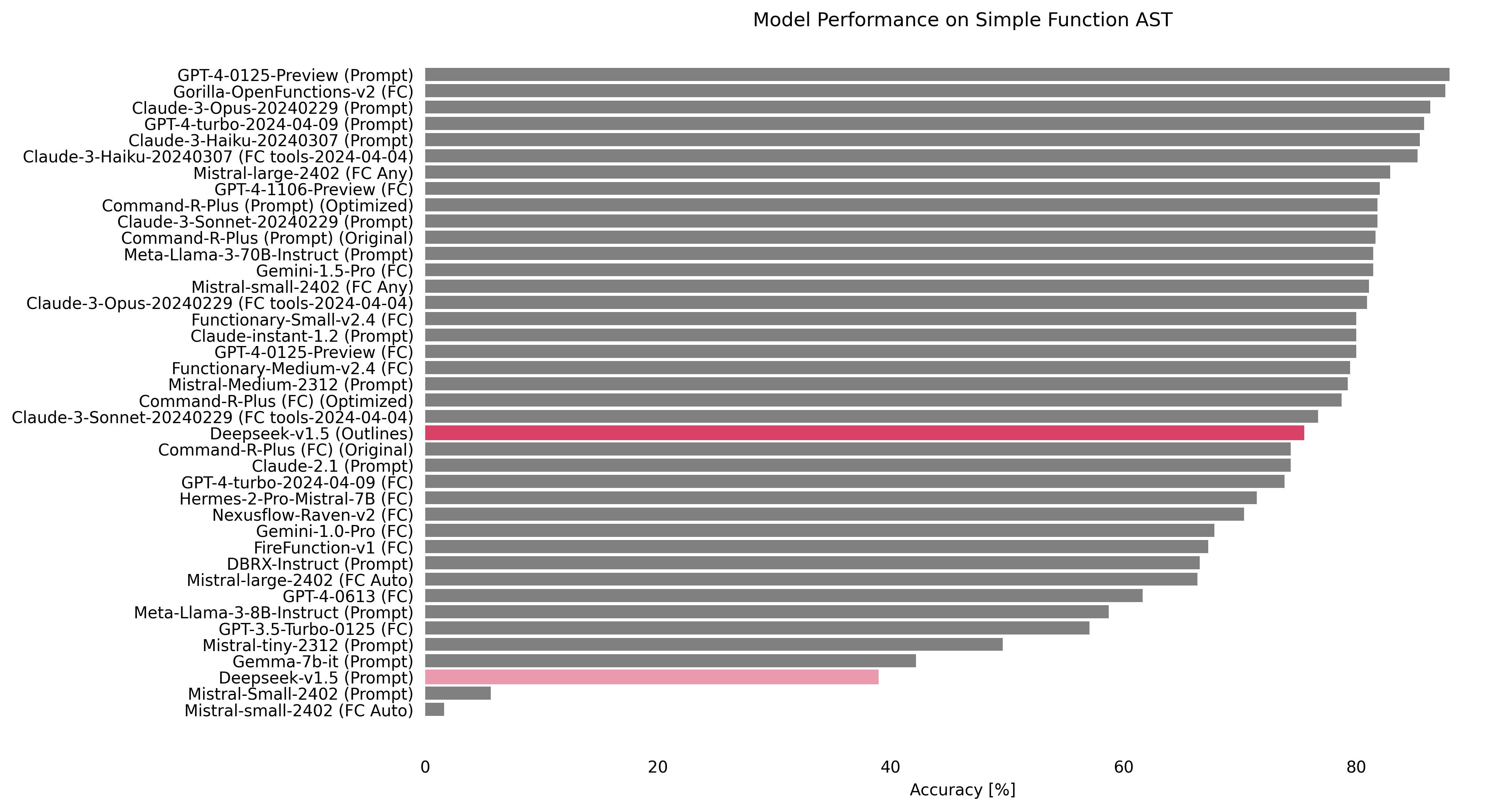
We directly compared how well structured generation works against fine-tuning. We chose deepseek-coder-7b-instruct-v1.5, a model that is used as the base for the fine-tuned Gorilla model. By combining it with Outlines, we saw a remarkable improvement in performance. The model jumped from the 38th position with an accuracy of 38.91% to the 3rd place, achieving 87%. This result is very important because it matches the performance of the fine-tuned Gorilla-OpenFunctions-v2 model, which is based on the same architecture. The success of this test raises important questions about the different ways to improve model performance. It suggests that structured generation may, in some cases, be a good and efficient alternative to fine-tuning.
Meta-Llama-3-8B-Instruct (from 34th, 58.73% to 7th, 84.25%)
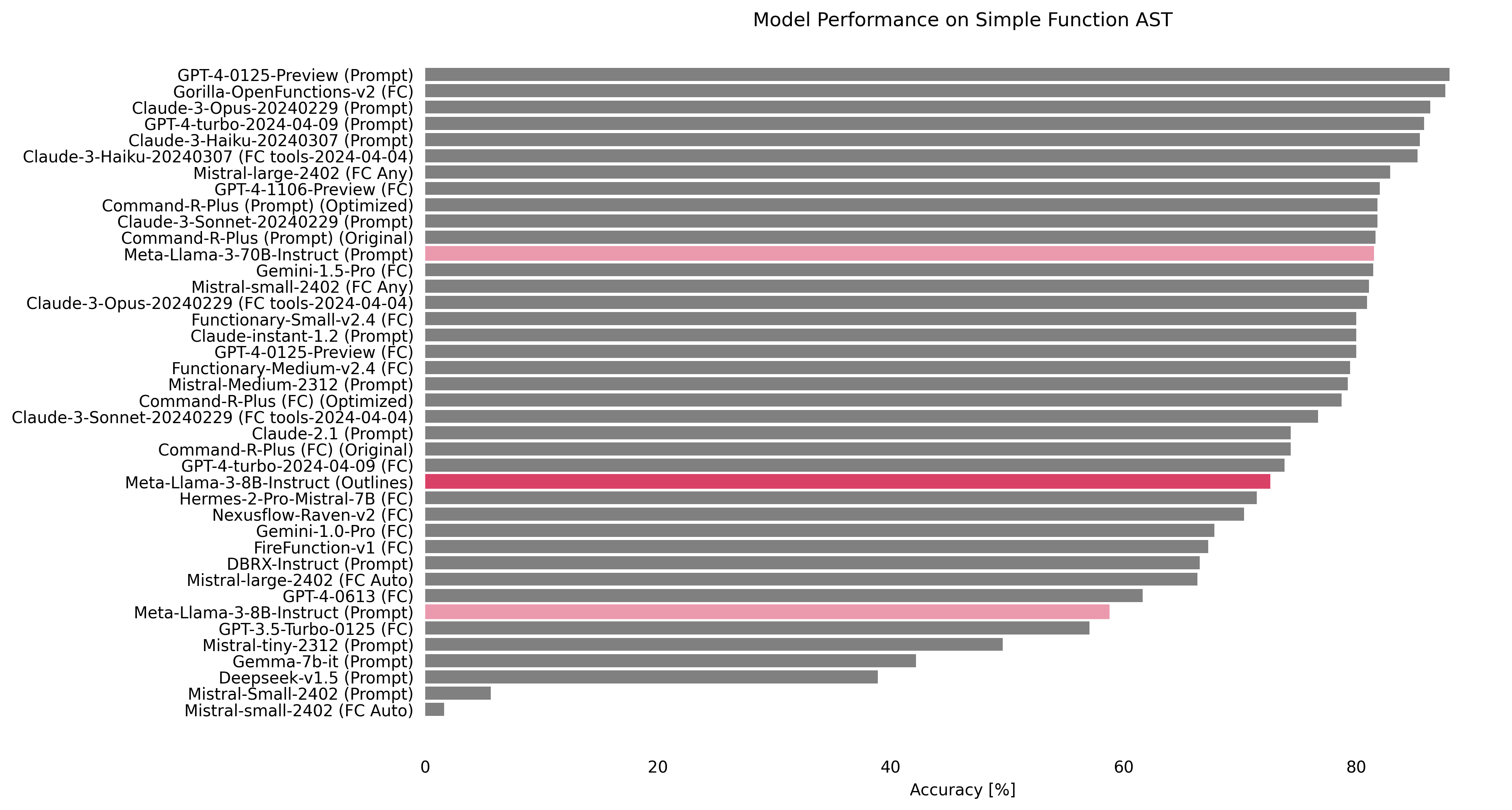
We tested the latest sensation in the world of language models. Meta-Llama-3-8B-Instruct achieved an impressive accuracy of 84.25%, securing the 7th position on the leaderboard.
Conclusion
Our study shows that structured generation significantly improves how LLMs handle function calling tasks. We found through testing that it matches traditional fine-tuning in terms of accuracy and efficiency, especially for smaller models. It also leads to better understanding of complex inputs. Looking ahead, we plan to expand our use of the GFCL benchmark’s evaluation categories and explore more diverse datasets.
Sign up using this form to receive an email whenever I post new content on my blog.
Footnotes
Willard, B. T., & Louf, R. (2023). Efficient Guided Generation for Large Language Models.↩︎
Yan, F., Mao, H., Ji, C. C.-J., Zhang, T., Patil, S. G., Stoica, I., & Gonzalez, J. E. (2024). Berkeley Function Calling Leaderboard.↩︎
Patil, S. G., Zhang, T., Wang, X., & Gonzalez, J. E. (2023). Gorilla: Large Language Model Connected with Massive APIs. arXiv preprint arXiv:2305.15334.↩︎